1号晚上听到两声春雷,我觉得它是在告诉我,春天到了,该发点什么了。
我说好啊好啊,这就来发博客。
我们先来看这段网页:

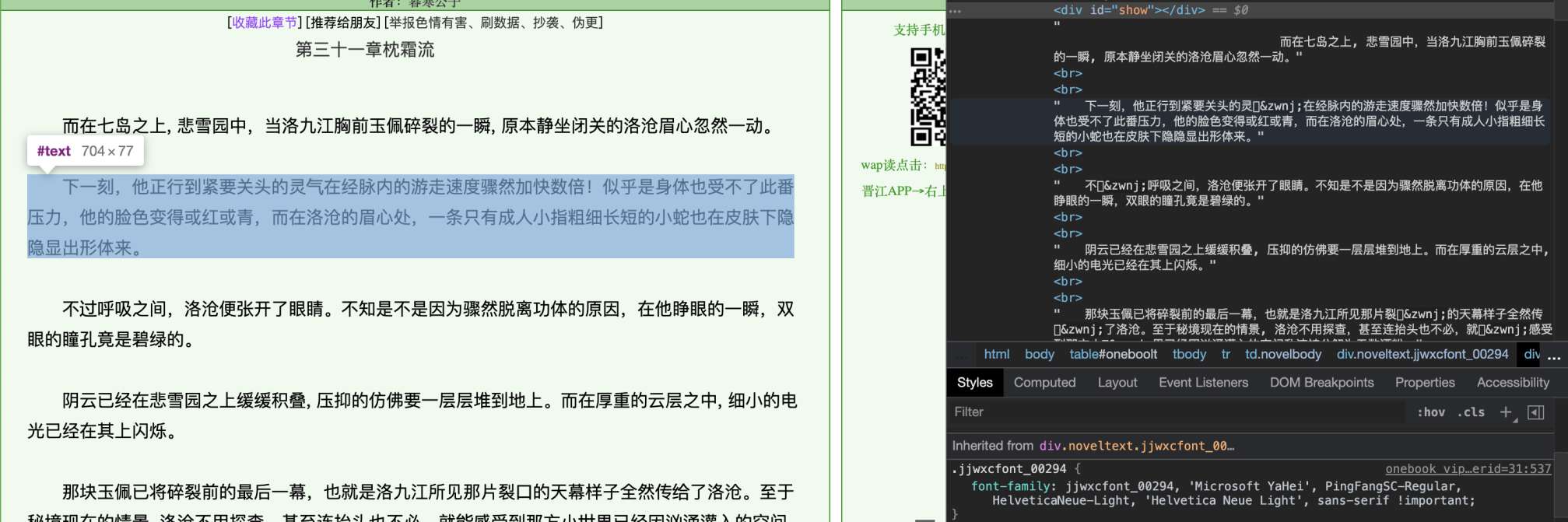
无限好文,尽在jjwxc
注意HTML中,许多字符的显示是方框。检查HTML源代码后发现,有些字符被替换成了这样的编码。
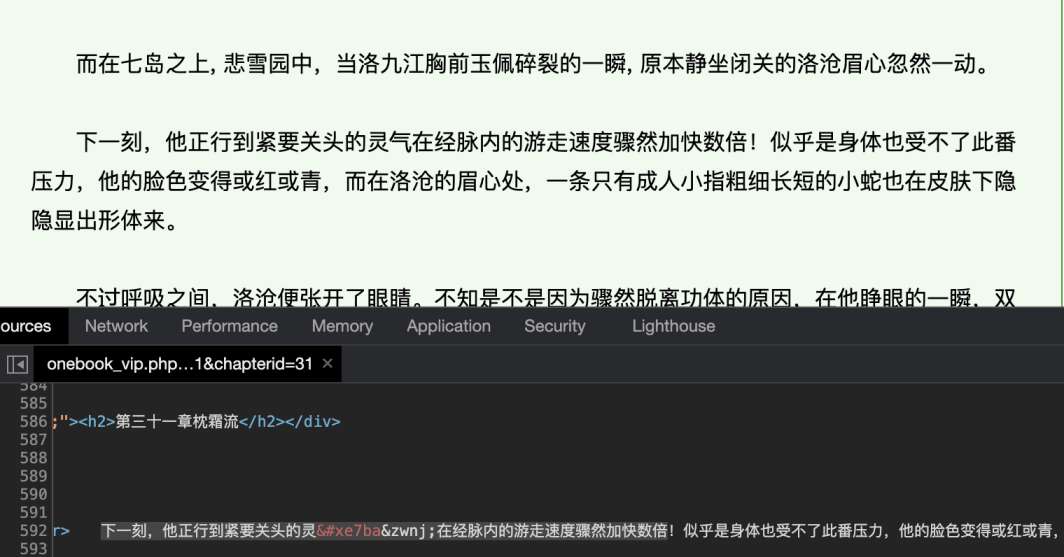

在第一张图中,可以发现当前的段落应用了名为jjwxcfont_00294的自定义字体。“气”字对应的UTF-8编码是6c14,GBK编码是c6f8,BIG5中是c9a,我觉得按照jj的技术水平,应该不会想到用别的编码集;所以e7ba应该不属于任何标准的编码集。而‌ 是防止粘连的特殊字符,因为使用非标准的编码,浏览器渲染时可能会把字符误当成粘连字符而和一个正常的字符重叠;在爬虫处理过程中直接去除即可。
解析字体
我们把这个自定义字体下载下来,然后用python的fonttools列举出其中所有的字符:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import re import requests import subprocess from fontTools.ttLib import TTFont ttf_path = "00294.ttf" # xiazai ttf_content = requests.get("http://static.jjwxc.net/tmp/fonts/jjwxcfont_00294.ttf") with open(ttf_path, "wb") as f: f.write(ttf_content.content) # jiexi ttf = TTFont(ttf_path, 0, allowVID=0, ignoreDecompileErrors=True, fontNumber=-1) ttf_chars = set() for x in ttf["cmap"].tables: for y in x.cmap.items(): char_unicode = chr(y[0]) if char_unicode == "x": continue ttf_chars.add(char_unicode) |
注意有些TTF字体中包含一个编码的多个字形,所以我们用set()来去重;并且舍弃了”x”字符。
因为无法辨认自定义字体中的编码对应的真实汉字,我们使用ImageMagick工具包中的convert来渲染字体,并且每行20个字符来分段,防止出现超长的棍子图片:
|
1 2 3 4 5 6 7 8 9 10 11 |
PER_LINE = 20 txt_path = ttf_path + ".txt" img_path = ttf_path + ".jpg" chars = list(ttf_chars) # fenduan xieru suoyou zifu with open(txt_path, "w") as f: f.write("\n".join(["".join(chars[i:i+PER_LINE]) for i in range(0, len(chars), PER_LINE)])) # shengcheng tupian subprocess.call(["convert", "-font", ttf_path, "-pointsize", "64", "-background", "rgba(255,255,255)", "label:@%s" % txt_path, img_path]) |
完成后得到如下图片:


我合理怀疑这就是微软雅黑
可以看到其中包含了200个常用字。通过翻阅章节可以发现自定义字体有复数多个,且其中每个字对应的内部编码均不相同,所以接下来我们需要一种自动化的方法来将自定义字体中的编码映射回原始文字。
识别字体
这里我们使用开源的tesseract工具来进行OCR识别。2021年了,tesseract都用上神经网络了,你还有理由不学点AI吗?


随便找的图,并不是恰饭
因为tesseract默认只能识别英语和数字,我们需要安装简体中文训练数据(chi_sim),可以从tessdata项目获得。安装完成后,验证训练数据能被加载:
|
1 2 3 4 5 6 |
$ tesseract --list-langs List of available languages (4): chi_sim eng osd snum |
然后我们调用tesseract来识别字符:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
tesseract_result = "00294" subprocess.call(["tesseract", img_path, tesseract_result, "-l", "chi_sim", "--psm", "6"]) char_map = {} with open(tesseract_result + ".txt") as f: # remove single byte characters ct = re.sub("[\x00-\x7F]+", "", f.read()) if len(chars) != len(ct): raise Exception("%d chars but %d recognized" % (len(chars), len(ct))) for i in range(len(chars)): char_map["%x" % ord(chars[i])] = ct[i] print(char_map) |
注意因为自动分段和分词的问题,tesseract会识别出奇怪的拉丁字符和数字,我们通过正则表达式把它们连同空白字符一起去除。
最后得到结果:
|
1 |
{'e2c7': '不', 'e8f0': '大', 'e7ba': '气', 'e803': '高', 'e0fe': '笑', 'e354': '行', 'eca5': '小', 'ece7': '代', 'ecdf': '者', 'e127': '重', 'eeb7': '中', 'e681': '要', 'e36e': '说', 'e306': '还', 'ef8c': '力', 'e809': '用', 'e9b9': '四', 'e737': '名', 'e589': '发', 'eb85': '种', 'ee46': '无', 'e3f5': '民', 'eec1': '事', 'e45a': '思', 'eaa5': '把', 'e851': '理', 'ef10': '法', 'e655': '关', 'e07f': '与', 'e21b': '到', 'ef9e': '三', 'efe8': '之', 'ed39': '由', 'e959': '起', 'e946': '声', 'e321': '问', 'e0b9': '得', 'e1c0': '回', 'e47b': '有', 'e800': '书', 'e9cb': '再', 'ebd8': '以', 'e45b': '也', 'e76e': '去', 'e05d': '对', 'e599': '性', 'ea48': '己', 'e966': '走', 'eefa': '子', 'e6aa': '两', 'e5b2': '分', 'eb7e': '老', 'eba0': '死', 'e370': '话', 'e6b1': '后', 'e793': '生', 'ecdc': '西', 'e8e4': '了', 'e435': '主', 'e523': '都', 'e8c4': '真', 'e9fb': '物', 'ea94': '个', 'e41c': '只', 'e84f': '会', 'e609': '正', 'e692': '别', 'e6b5': '少', 'e50e': '道', 'e0af': '文', 'e776': '而', 'e11c': '更', 'e85a': '于', 'e50d': '看', 'e799': '着', 'ee0c': '身', 'e3f1': '然', 'ef56': '这', 'e143': '二', 'e00f': '间', 'ee9d': '相', 'e9a6': '成', 'e438': '公', 'e2f2': '过', 'ea59': '向', 'e159': '样', 'e877': '又', 'eacc': '同', 'ece8': '意', 'ee49': '因', 'eefd': '听', 'ee8f': '论', 'eeaf': '见', 'e652': '十', 'eea4': '第', 'e5e2': '定', 'e4ba': '前', 'e070': '动', 'e52d': '神', 'eae9': '史', 'e64e': '却', 'e7df': '知', 'e430': '那', 'e87a': '门', 'e732': '眼', 'e183': '给', 'e772': '部', 'efbc': '上', 'e037': '它', 'edae': '才', 'e895': '体', 'e1b5': '点', 'e731': '学', 'e84a': '头', 'ec45': '口', 'ea25': '已', 'ee72': '在', 'efa8': '能', 'e6d2': '我', 'ed78': '义', 'eb7b': '是', 'ea6a': '国', 'eeb2': '感', 'e52b': '白', 'e68a': '可', 'e2d8': '就', 'e8b6': '家', 'eba9': '美', 'e974': '便', 'eec2': '日', 'e7f6': '社', 'e5cd': '年', 'ed1a': '长', 'efe7': '并', 'e525': '里', 'eb89': '太', 'ea6e': '她', 'e26b': '他', 'e2e3': '被', 'e663': '世', 'efa4': '使', 'e296': '化', 'e6de': '何', 'ee87': '好', 'eccd': '多', 'e4e2': '几', 'e156': '最', 'e727': '本', 'e3fb': '些', 'e498': '等', 'efd8': '没', 'efe3': '来', 'e997': '外', 'eb0c': '其', 'ea98': '下', 'e878': '什', 'e5d7': '地', 'e14b': '如', 'e7a7': '你', 'ec5d': '全', 'edd1': '天', 'e0c5': '出', 'e18f': '特', 'e866': '女', 'e01d': '们', 'e8ed': '想', 'ecab': '一', 'e45f': '打', 'e9dd': '此', 'ee50': '但', 'eb9d': '时', 'e0c6': '力', 'eb62': '先', 'eef4': '作', 'e1fc': '实', 'e58b': '儿', 'ef2f': '教', 'e094': '方', 'ec21': '情', 'e17b': '人', 'e134': '进', 'e51f': '当', 'e0b6': '和', 'e2be': '将', 'e7a2': '自', 'ea8c': '心', 'ec70': '明', 'ee0d': '手', 'e7e2': '很', 'e56e': '开', 'eea1': '的', 'e360': '面', 'e0cb': '现', 'e35a': '所', 'e2dd': '从', 'eaff': '经', 'eefc': '么', 'efe5': '写', 'eb04': '果', 'e99b': '新'} |
之前看到的e7ba确实被成功识别成了“气”。
提高效率和准确率
使用OCR当然是简单,但是一来速度慢(包好200个字符的单个字体需要5~10秒),二来由于没人知道神经网络里面具体发生了什么,在不同的字符排列顺序下,可能会出现误识别。通过比较OCR识别结果和字体中的Glyph(可以认为是字体中每个字的矢量表示)我们可以发现:
- 这个网站的所有字体中使用了相同的200个常用字
- 所有字体中代表相同字的Glyph路径完全相同
那么我们可以作出以下的优化:
- 在生成图片时,将字符按已知可正确识别的特定顺序排序(但实现起来还是比较冗杂)
- 比较所有的OCR结果,如果有多个字体的OCR结果相同,则认为是可信的
- 将可信结果中的某个字体的Glyph路径作为参考,与新字体的Glyph路径比较;如果相同则认为是同一个字
- 如果未来jj随机化Glyph中的坐标点,也可以分别计算每个点的距离,在一定范围内则认为近似相同
- 持续用OCR结果来验证路径比较结果
我把除了第一点的完整实现代码分享到了JJGet项目,链接中是一个服务端,将处理结果返回给JJGet。目前测试结果非常理想,感兴趣的朋友可以去康康。