本文中所有软件在这里:https://pan.quark.cn/s/8919c40fcd57
下载Sunshine
下载地址 https://github.com/LizardByte/Sunshine/releases/tag/v0.21.0
如果你平时根本不开显示器而用远程桌面登录,需要这个fix https://github.com/fffonion/Sunshine/releases/tag/0.21-fix
(详见Sunshine 的权限提升实现的坑)
如果使用portable版,需要运行 scripts/install-service.bat 安装服务,用来支持后面的权限提升操作。
安装Amyuni 虚拟显示驱动
下载地址 https://www.amyuni.com/forum/viewtopic.php?t=3030
因为显卡需要检测到连接的显示器才会输出视频信号,安装虚拟显示驱动即可不插显示器串流。
另外,也可以购买HDMI诱骗器。
配置远程桌面
非必需,用来手滑误操作时的救援。
注意,远程桌面也使用了虚拟显示器,并且在开启远程桌面时,会屏蔽其他所有的显示器。因此串流时应关闭远程桌面,另外也不能在远程桌面中直接启动 Sunshine,否则会检测不到正确的显示器。可以使用以下命令
|
|
timeout 10 && D:\Sunshine\sunshine.exe |
在远程桌面中运行后,立即关闭远程桌面,即可在非远程桌面环境中启动 Sunshine。
查找虚拟显示器序号
在 Sunshine 目录中,运行 scripts\dxgi-info.exe 程序,寻找除了 \\.\DISPLAY1 以外的显示器。
配置 Sunshine
- 在 Applications 选项卡中,点击 + Add New
- 在 Command 中,填写下列命令打开触摸UI
|
|
"D:\Genshin Impact Game\YuanShen.exe" use_mobile_platform -is_cloud 1 -platform_type CLOUD_THIRD_PARTY_MOBILE -borderless -popupwindow |
|
|
"D:\Genshin Impact Game\YuanShen.exe" -borderless -popupwindow |
- 勾选 Run as administrator
- 点 Save 保存
自动适配分辨率
在新建的 Application 的 Do Command 中添加如下项
|
|
cmd /C reg add "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\WUDF\Services\usbmmIdd\Parameters\Monitors" /v "2" /t REG_SZ /d %SUNSHINE_CLIENT_WIDTH%,%SUNSHINE_CLIENT_HEIGHT% /f |
|
|
cmd /C D:\usbmmidd_v2\deviceinstaller64.exe enableidd 0 |
|
|
cmd /C D:\usbmmidd_v2\deviceinstaller64.exe enableidd 1 |
- 设置主显示器为虚拟显示器,注意修改 5 为上一步中找到的虚拟显示器序号
|
|
cmd /C D:\Games\Tools\MultiMonitorTool.exe /SetPrimary 5 |
另外,在Undo Command中填写
|
|
cmd /C D:\Games\Tools\MultiMonitorTool.exe /SetPrimary 1 |
用来恢复默认主显示器
|
|
cmd /C D:\Games\Tools\QRes.exe /X:%SUNSHINE_CLIENT_WIDTH% /Y:%SUNSHINE_CLIENT_HEIGHT% |
|
|
cmd /C reg add HKCU\Software\miHoYo\原神 /v "Screenmanager Resolution Width_h182942802" /t REG_DWORD /d %SUNSHINE_CLIENT_WIDTH% /f |
|
|
cmd /C reg add HKCU\Software\miHoYo\原神 /v "Screenmanager Resolution Height_h2627697771" /t REG_DWORD /d %SUNSHINE_CLIENT_HEIGHT% /f |
以上所有命令均需要勾选 Elevated 复选框。
如果在运行时遇到权限提升失败,检查服务是否已启用,并可以尝试重启 Sunshine。
安装 Moonlight 客户端
手机端使用 阿西西大佬 修改的多点触控版本 https://www.bilibili.com/video/BV1Si4y1Y7Jb/。
iOS可以使用 sideloadly 自签名安装。
PC端使用官方客户端即可。
进入后,在 Settings 中设置分辨率为当前设备的分辨率;手机端的Touch Mode 选择 Touchscreen。
配置 Wireguard 公网串流
在路由器端配置 Wireguard 隧道,或者在手机端配置 Wireguard 隧道,并设置路由规则。
登录Windows
使用Sunshine 的 Desktop 程序,或者在物理显示器上登录一次。注意远程桌面登录的没用。
效果
30M码率在 iPad Mini 6上流畅地公网串流,PC端开启1.5倍渲染高画质,比官方的云原神(10M码率)清晰不少,画质也提高了w
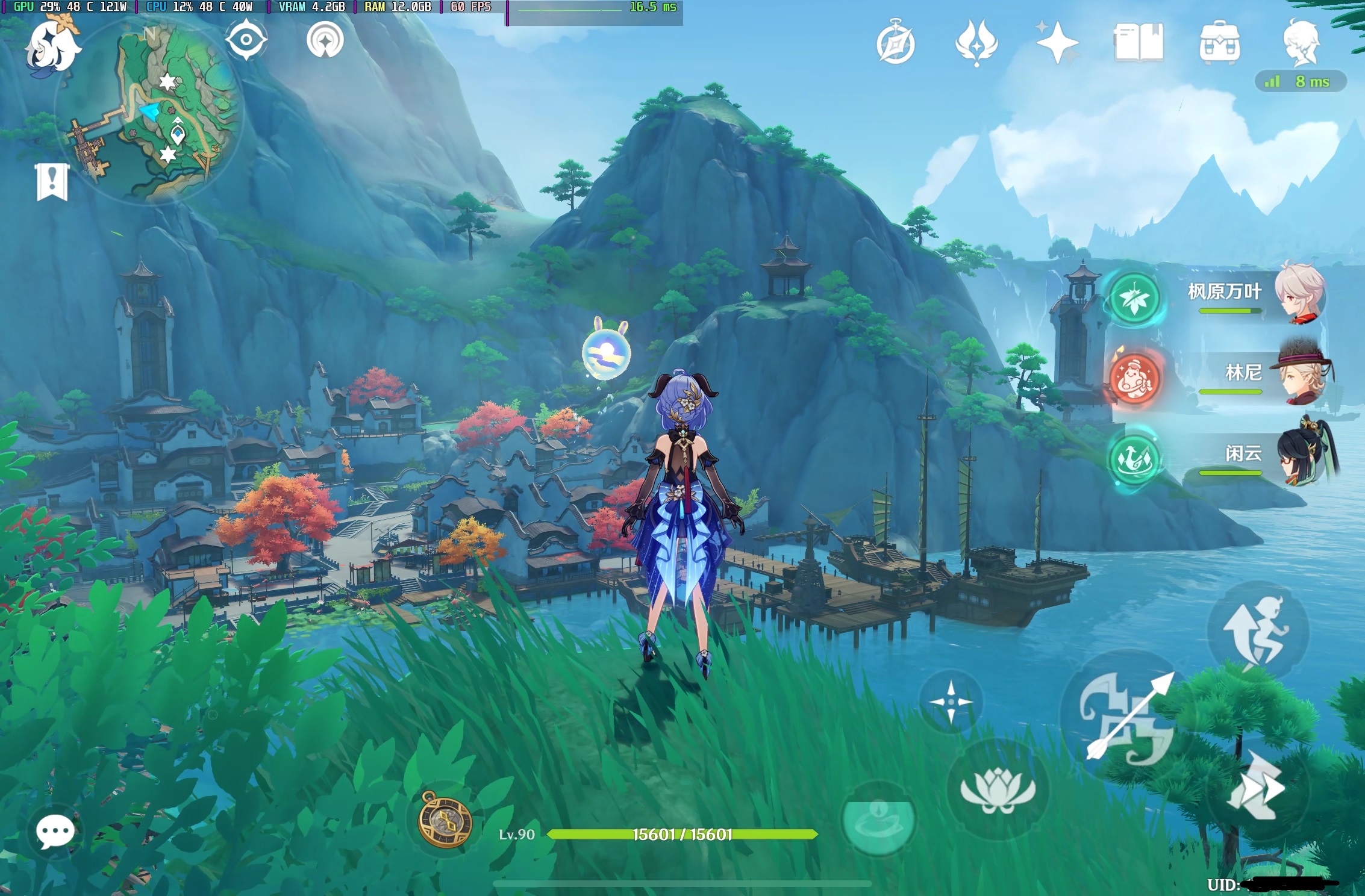
官方云原神: