1號晚上聽到兩聲春雷,我覺得它是在告訴我,春天到了,該發點什麼了。
我說好啊好啊,這就來發博客。
我們先來看這段網頁:
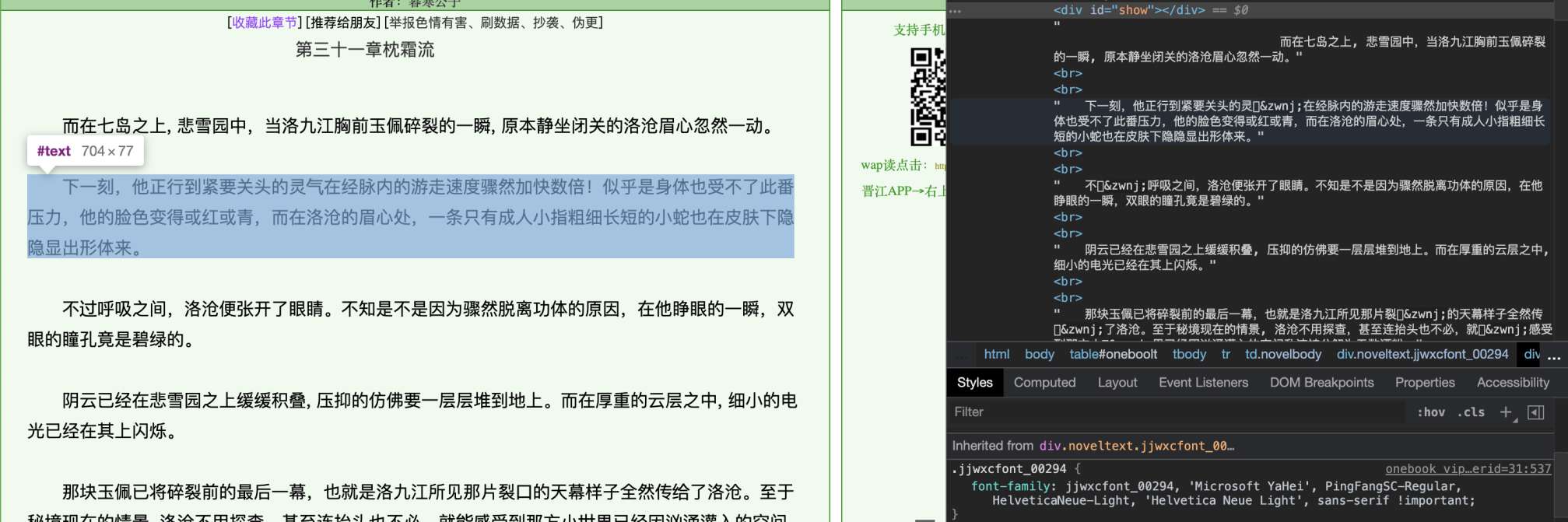
無限好文,盡在jjwxc
注意HTML中,許多字符的顯示是方框。檢查HTML源代碼後發現,有些字符被替換成了這樣的編碼。
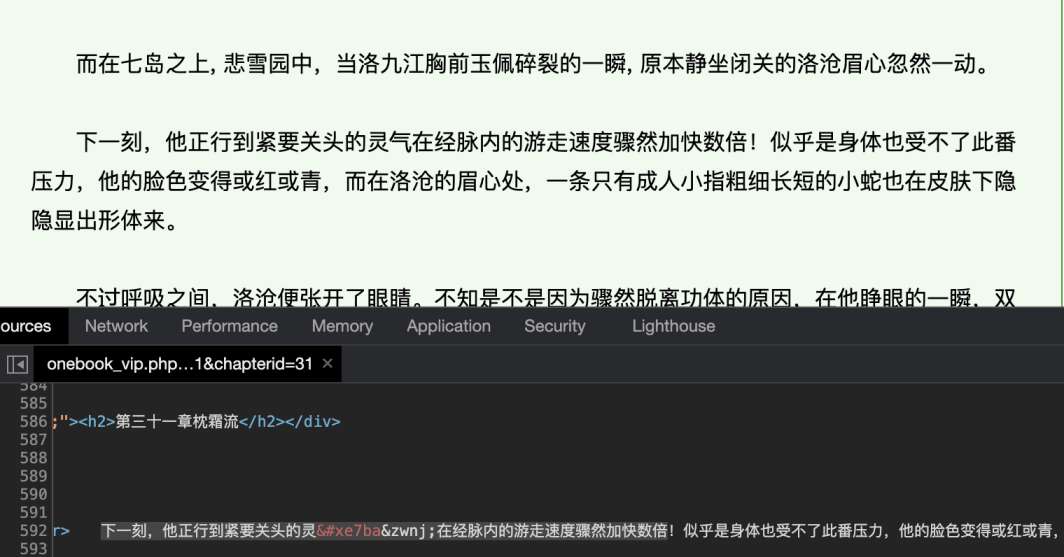
在第一張圖中,可以發現當前的段落應用了名為jjwxcfont_00294的自定義字體。“氣”字對應的UTF-8編碼是6c14,GBK編碼是c6f8,BIG5中是c9a,我覺得按照jj的技術水平,應該不會想到用別的編碼集;所以e7ba應該不屬於任何標準的編碼集。而‌ 是防止粘連的特殊字符,因為使用非標準的編碼,瀏覽器渲染時可能會把字符誤當成粘連字符而和一個正常的字符重疊;在爬蟲處理過程中直接去除即可。
解析字體
我們把這個自定義字體下載下來,然後用python的fonttools列舉出其中所有的字符:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import re import requests import subprocess from fontTools.ttLib import TTFont ttf_path = "00294.ttf" # xiazai ttf_content = requests.get("http://static.jjwxc.net/tmp/fonts/jjwxcfont_00294.ttf") with open(ttf_path, "wb") as f: f.write(ttf_content.content) # jiexi ttf = TTFont(ttf_path, 0, allowVID=0, ignoreDecompileErrors=True, fontNumber=-1) ttf_chars = set() for x in ttf["cmap"].tables: for y in x.cmap.items(): char_unicode = chr(y[0]) if char_unicode == "x": continue ttf_chars.add(char_unicode) |
注意有些TTF字體中包含一個編碼的多個字形,所以我們用set()來去重;並且捨棄了”x”字符。
因為無法辨認自定義字體中的編碼對應的真實漢字,我們使用ImageMagick工具包中的convert來渲染字體,並且每行20個字符來分段,防止出現超長的棍子圖片:
|
1 2 3 4 5 6 7 8 9 10 11 |
PER_LINE = 20 txt_path = ttf_path + ".txt" img_path = ttf_path + ".jpg" chars = list(ttf_chars) # fenduan xieru suoyou zifu with open(txt_path, "w") as f: f.write("\n".join(["".join(chars[i:i+PER_LINE]) for i in range(0, len(chars), PER_LINE)])) # shengcheng tupian subprocess.call(["convert", "-font", ttf_path, "-pointsize", "64", "-background", "rgba(255,255,255)", "label:@%s" % txt_path, img_path]) |
完成後得到如下圖片:

我合理懷疑這就是微軟雅黑
可以看到其中包含了200個常用字。通過翻閱章節可以發現自定義字體有複數多個,且其中每個字對應的內部編碼均不相同,所以接下來我們需要一種自動化的方法來將自定義字體中的編碼映射回原始文字。
識別字體
這裡我們使用開源的tesseract工具來進行OCR識別。2021年了,tesseract都用上神經網絡了,你還有理由不學點AI嗎?

隨便找的圖,並不是恰飯
因為tesseract默認只能識別英語和數字,我們需要安裝簡體中文訓練數據(chi_sim),可以從tessdata項目獲得。安裝完成後,驗證訓練數據能被加載:
|
1 2 3 4 5 6 |
$ tesseract --list-langs List of available languages (4): chi_sim eng osd snum |
然後我們調用tesseract來識別字符:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
tesseract_result = "00294" subprocess.call(["tesseract", img_path, tesseract_result, "-l", "chi_sim", "--psm", "6"]) char_map = {} with open(tesseract_result + ".txt") as f: # remove single byte characters ct = re.sub("[\x00-\x7F]+", "", f.read()) if len(chars) != len(ct): raise Exception("%d chars but %d recognized" % (len(chars), len(ct))) for i in range(len(chars)): char_map["%x" % ord(chars[i])] = ct[i] print(char_map) |
注意因為自動分段和分詞的問題,tesseract會識別出奇怪的拉丁字符和數字,我們通過正則表達式把它們連同空白字符一起去除。
最後得到結果:
|
1 |
{'e2c7': '不', 'e8f0': '大', 'e7ba': '氣', 'e803': '高', 'e0fe': '笑', 'e354': '行', 'eca5': '小', 'ece7': '代', 'ecdf': '者', 'e127': '重', 'eeb7': '中', 'e681': '要', 'e36e': '說', 'e306': '還', 'ef8c': '力', 'e809': '用', 'e9b9': '四', 'e737': '名', 'e589': '發', 'eb85': '種', 'ee46': '無', 'e3f5': '民', 'eec1': '事', 'e45a': '思', 'eaa5': '把', 'e851': '理', 'ef10': '法', 'e655': '關', 'e07f': '與', 'e21b': '到', 'ef9e': '三', 'efe8': '之', 'ed39': '由', 'e959': '起', 'e946': '聲', 'e321': '問', 'e0b9': '得', 'e1c0': '回', 'e47b': '有', 'e800': '書', 'e9cb': '再', 'ebd8': '以', 'e45b': '也', 'e76e': '去', 'e05d': '對', 'e599': '性', 'ea48': '己', 'e966': '走', 'eefa': '子', 'e6aa': '兩', 'e5b2': '分', 'eb7e': '老', 'eba0': '死', 'e370': '話', 'e6b1': '後', 'e793': '生', 'ecdc': '西', 'e8e4': '了', 'e435': '主', 'e523': '都', 'e8c4': '真', 'e9fb': '物', 'ea94': '個', 'e41c': '只', 'e84f': '會', 'e609': '正', 'e692': '別', 'e6b5': '少', 'e50e': '道', 'e0af': '文', 'e776': '而', 'e11c': '更', 'e85a': '於', 'e50d': '看', 'e799': '着', 'ee0c': '身', 'e3f1': '然', 'ef56': '這', 'e143': '二', 'e00f': '間', 'ee9d': '相', 'e9a6': '成', 'e438': '公', 'e2f2': '過', 'ea59': '向', 'e159': '樣', 'e877': '又', 'eacc': '同', 'ece8': '意', 'ee49': '因', 'eefd': '聽', 'ee8f': '論', 'eeaf': '見', 'e652': '十', 'eea4': '第', 'e5e2': '定', 'e4ba': '前', 'e070': '動', 'e52d': '神', 'eae9': '史', 'e64e': '卻', 'e7df': '知', 'e430': '那', 'e87a': '門', 'e732': '眼', 'e183': '給', 'e772': '部', 'efbc': '上', 'e037': '它', 'edae': '才', 'e895': '體', 'e1b5': '點', 'e731': '學', 'e84a': '頭', 'ec45': '口', 'ea25': '已', 'ee72': '在', 'efa8': '能', 'e6d2': '我', 'ed78': '義', 'eb7b': '是', 'ea6a': '國', 'eeb2': '感', 'e52b': '白', 'e68a': '可', 'e2d8': '就', 'e8b6': '家', 'eba9': '美', 'e974': '便', 'eec2': '日', 'e7f6': '社', 'e5cd': '年', 'ed1a': '長', 'efe7': '並', 'e525': '里', 'eb89': '太', 'ea6e': '她', 'e26b': '他', 'e2e3': '被', 'e663': '世', 'efa4': '使', 'e296': '化', 'e6de': '何', 'ee87': '好', 'eccd': '多', 'e4e2': '幾', 'e156': '最', 'e727': '本', 'e3fb': '些', 'e498': '等', 'efd8': '沒', 'efe3': '來', 'e997': '外', 'eb0c': '其', 'ea98': '下', 'e878': '什', 'e5d7': '地', 'e14b': '如', 'e7a7': '你', 'ec5d': '全', 'edd1': '天', 'e0c5': '出', 'e18f': '特', 'e866': '女', 'e01d': '們', 'e8ed': '想', 'ecab': '一', 'e45f': '打', 'e9dd': '此', 'ee50': '但', 'eb9d': '時', 'e0c6': '力', 'eb62': '先', 'eef4': '作', 'e1fc': '實', 'e58b': '兒', 'ef2f': '教', 'e094': '方', 'ec21': '情', 'e17b': '人', 'e134': '進', 'e51f': '當', 'e0b6': '和', 'e2be': '將', 'e7a2': '自', 'ea8c': '心', 'ec70': '明', 'ee0d': '手', 'e7e2': '很', 'e56e': '開', 'eea1': '的', 'e360': '面', 'e0cb': '現', 'e35a': '所', 'e2dd': '從', 'eaff': '經', 'eefc': '么', 'efe5': '寫', 'eb04': '果', 'e99b': '新'} |
之前看到的e7ba確實被成功識別成了“氣”。
提高效率和準確率
使用OCR當然是簡單,但是一來速度慢(包好200個字符的單個字體需要5~10秒),二來由於沒人知道神經網絡裡面具體發生了什麼,在不同的字符排列順序下,可能會出現誤識別。通過比較OCR識別結果和字體中的Glyph(可以認為是字體中每個字的矢量表示)我們可以發現:
- 這個網站的所有字體中使用了相同的200個常用字
- 所有字體中代表相同字的Glyph路徑完全相同
那麼我們可以作出以下的優化:
- 在生成圖片時,將字符按已知可正確識別的特定順序排序(但實現起來還是比較冗雜)
- 比較所有的OCR結果,如果有多個字體的OCR結果相同,則認為是可信的
- 將可信結果中的某個字體的Glyph路徑作為參考,與新字體的Glyph路徑比較;如果相同則認為是同一個字
- 如果未來jj隨機化Glyph中的坐標點,也可以分別計算每個點的距離,在一定範圍內則認為近似相同
- 持續用OCR結果來驗證路徑比較結果
我把除了第一點的完整實現代碼分享到了JJGet項目,鏈接中是一個服務端,將處理結果返回給JJGet。目前測試結果非常理想,感興趣的朋友可以去康康。
