因为听到了两声雷,所以要发两篇博客。
——鲁迅
这篇博客来聊聊LuaJIT FFI里面ctypes的实现。
FFI全称是Foreign Function Interface即异世界语言接口,LuaJIT中使用FFI可以调用其他语言编译的库。
一个示例如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
local ffi = require("ffi") local C = ffi.C ffi.cdef [[ typedef unsigned int time_t; typedef unsigned int suseconds_t; typedef struct timeval { time_t tv_sec; suseconds_t tv_usec; } timeval; typedef struct timezone { int tz_minuteswest; int tz_dsttime; } timezone; int gettimeofday(struct timeval *tv, struct timezone *tz); ]] local tv = ffi.new("timeval[1]") local tz = ffi.new("timezone[1]") C.gettimeofday(tv, tz) print(tv[1].tv_sec) print(tz[1].tz_dsttime) print("tv_sec in timeval offset:", ffi.offsetof(tv[1], "tv_sec")) print("tv_usec in timeval offset:", ffi.offsetof(tv[1], "tv_usec")) |
以上示例会输出
991970
0
tv_sec in timeval offset:0
tv_usec in timeval offset:4
有关FFI的具体语法不想写了,感兴趣的朋友可以看LuaJIT关于FFI的四篇文档。看完之后可以再看看同事的一个讲座。
在上面这个示例中,我们定义了time_t和suseconds_t作为int_t的别名,timeval和timezone两个结构体,和gettimeofday这个函数的签名。简单地说,FFI首先会在当前进程映像中找到gettimeofday的偏移,由于这个C函数在libc中实现,所以一定会在当前映像中找到。根据函数签名,将输入值按定义的数据类型长度压入栈中;然后,当取值时,FFI根据当前平台和架构计算结构体中每个成员的偏移量,然后直接取出内存中对应偏移下对应字长的数据。
虽然ffi.cdef定义时的语法和C一样,但是FFI并没有真正编译它,而只是将它们按规则转换成偏移量,并且记录下来。
不论是enum,typedef还是function,LuaJIT FFI都用一种ctypes来表示它。为了方便用户不用重新定义像uint32_t这样的类型,LuaJIT自带了95种初始的ctypes。在这里推荐一个工具parseback,可以方便查看各个已定义的ctypes的类型。这个工具依赖的是一个没有文档的方法ffi.typeinfo:
|
1 2 3 4 5 |
local pp = require("parseback.parseback") for i=1,95 do print(i, ":", pp.typeinfo(i).c) end |
输出:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
1:void 2:const void 3:bool 4:const char 5:char 6:unsigned char 7:short 8:unsigned short 9:int 10:unsigned int 11:long 12:unsigned long 13:float 14:double 15:complex float 16:complex double 17:void * 18:const void * 19:const char * 20:const char [0] 21:enum { } 22:typedef void * va_list; 23:typedef void * __builtin_va_list; 24:typedef void * __gnuc_va_list; 25:typedef long ptrdiff_t; 26:typedef unsigned long size_t; 27:typedef int wchar_t; 28:typedef char int8_t; 29:typedef short int16_t; 30:typedef int int32_t; 31:typedef long int64_t; 32:typedef unsigned char uint8_t; 33:typedef unsigned short uint16_t; 34:typedef unsigned int uint32_t; 35:typedef unsigned long uint64_t; 36:typedef long intptr_t; 37:typedef unsigned long uintptr_t; 38:typedef long ssize_t; 39:/* keyword void: 269 */ 40:/* keyword _Bool: 270 */ 41:/* keyword bool: 270 */ 42:/* keyword char: 271 */ 43:/* keyword int: 272 */ 44:/* keyword __int8: 272 */ 45:/* keyword __int16: 272 */ 46:/* keyword __int32: 272 */ 47:/* keyword __int64: 272 */ 48:/* keyword float: 273 */ 49:/* keyword double: 273 */ 50:/* keyword long: 274 */ 51:/* keyword short: 276 */ 52:/* keyword _Complex: 277 */ 53:/* keyword complex: 277 */ 54:/* keyword __complex: 277 */ 55:/* keyword __complex__: 277 */ 56:/* keyword signed: 278 */ 57:/* keyword __signed: 278 */ 58:/* keyword __signed__: 278 */ 59:/* keyword unsigned: 279 */ 60:/* keyword const: 280 */ 61:/* keyword __const: 280 */ 62:/* keyword __const__: 280 */ 63:/* keyword volatile: 281 */ 64:/* keyword __volatile: 281 */ 65:/* keyword __volatile__: 281 */ 66:/* keyword restrict: 282 */ 67:/* keyword __restrict: 282 */ 68:/* keyword __restrict__: 282 */ 69:/* keyword inline: 283 */ 70:/* keyword __inline: 283 */ 71:/* keyword __inline__: 283 */ 72:/* keyword typedef: 284 */ 73:/* keyword extern: 285 */ 74:/* keyword static: 286 */ 75:/* keyword auto: 287 */ 76:/* keyword register: 288 */ 77:/* keyword __extension__: 289 */ 78:/* keyword __attribute: 291 */ 79:/* keyword __attribute__: 291 */ 80:/* keyword asm: 290 */ 81:/* keyword __asm: 290 */ 82:/* keyword __asm__: 290 */ 83:/* keyword __declspec: 292 */ 84:/* keyword __cdecl: 293 */ 85:/* keyword __thiscall: 293 */ 86:/* keyword __fastcall: 293 */ 87:/* keyword __stdcall: 293 */ 88:/* keyword __ptr32: 294 */ 89:/* keyword __ptr64: 294 */ 90:/* keyword struct: 295 */ 91:/* keyword union: 296 */ 92:/* keyword enum: 297 */ 93:/* keyword sizeof: 298 */ 94:/* keyword __alignof: 299 */ 95:/* keyword __alignof__: 299 */ |
可以看到许多关键词也被加入了初始列表中,这是为了防止熊孩子乱用关键词做类型名称。
parseback工具还能生成一个dot图来描述ctype,我们来看看之前的gettimeofday是怎么表示的:
|
1 2 3 4 5 6 7 8 9 |
local i = 96 while true do if not ffi.typeinfo(i) then i = i-1 break end i = i + 1 end print(pp.dot(i)) |
因为OpenResty也定义了一堆FFI类型,所以我们用一个循环来寻找ctypes表里面的最后一个类型,然后用以下命令
resty test.lua | dot -Tpng > 1.png
得到这样的图:
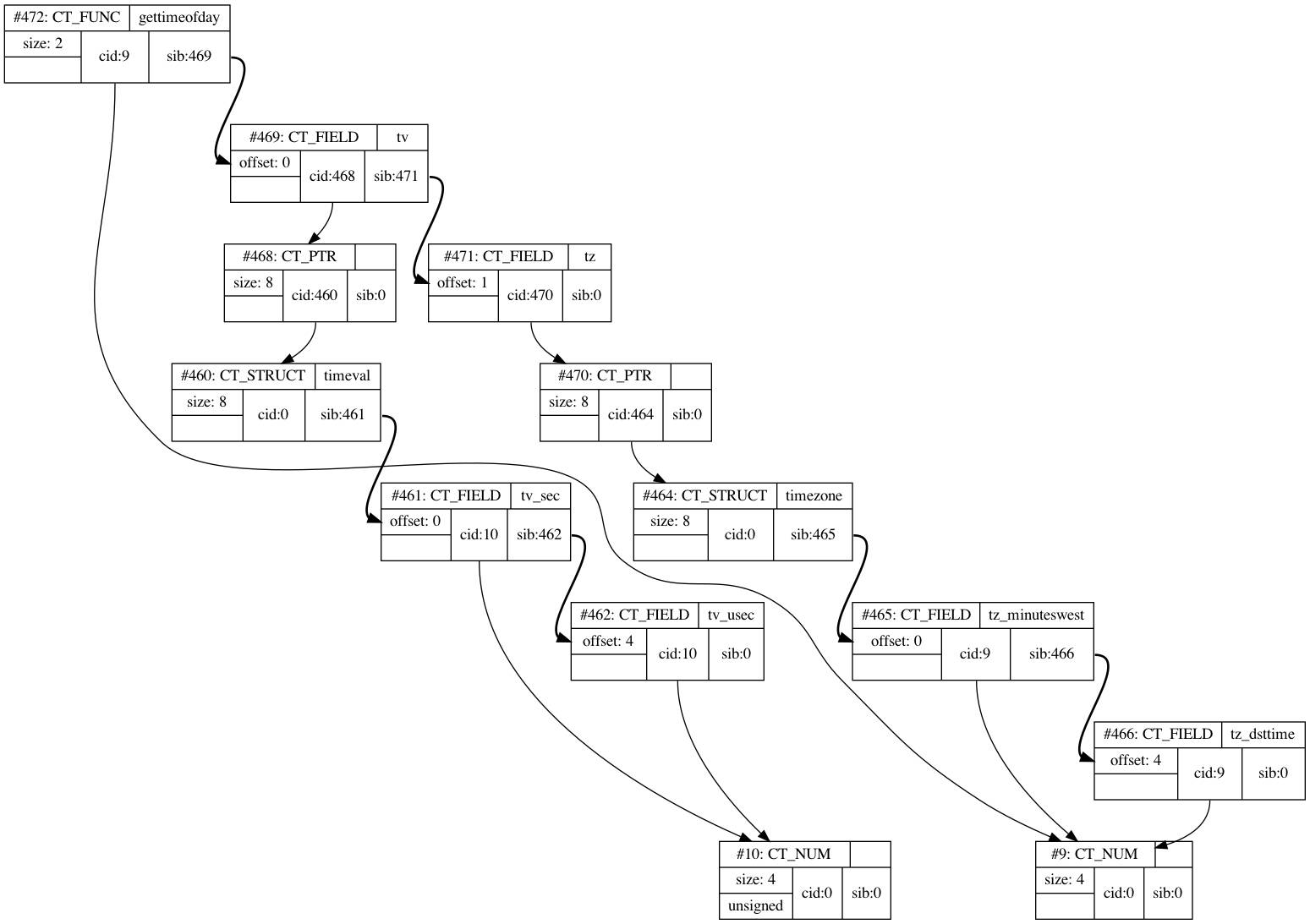
这个图好像有点复杂,我们先看看其中id为460的timeval结构体。
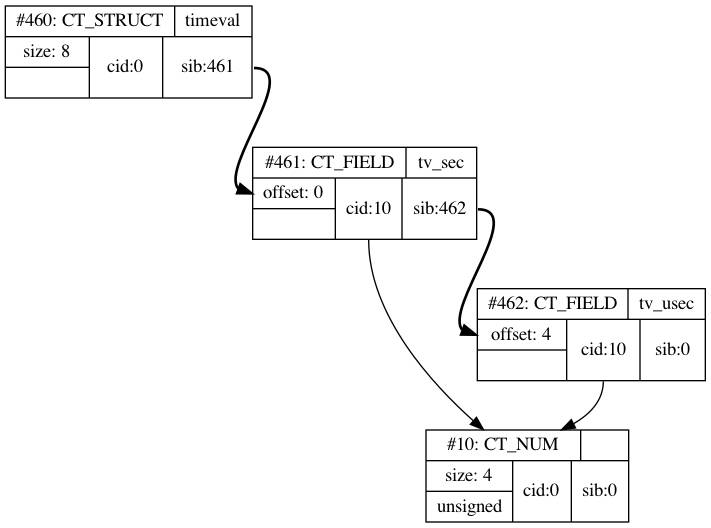
首先它的类型是CT_STRUCT,代表它是一个结构体的开始。
它的size是8,FFI通过这个属性知道当ffi.new(“timeval”)被调用时,需要分配多少内存。
它的cid(child ID)是0,这里先跳过。
它有一个sid(sibling ID)属性,值为461,它代表单链表的下一个成员。timeval由两个成员构成,分别是tv_sec和tv_usec;两个成员都有指为10的cid,对CT_FIELD来说,cid代表这个成员的类型,在这里它们都是size为4的CT_NUM。LuaJIT不会在类型上区分int,uint,long,它们都是CT_NUM,区别在于size和unsigned标记。如id为10的类型就是一个unsigned int。tv_usec的offset是4,代表它在结构体里的偏移量;当取timeval的tv_usec成员时,FFI跳过4字节,取它的类型长度也就是4字节内存。
我们再回到前一张复杂的图。
gettimeofday是个CT_FUNC类型的ctype,也就是function;当一个ctype是CT_FUNC时,它的cid表示返回值的类型,这个例子里是9,也就是signed int。
对一个CT_FUNC来说,sid代表参数列表的类型。sid值是469,指向了名为tv的CT_FIELD,它代表一个成员名称;LuaJIT在存储函数类型时,其实和存储一个结构体是类似的。id为469的CT_FIELD的cid为468,表示它的类型是468;468是一个指针CT_PTR,指向id是460的timeval结构体CT_STRUCT。连起来就是说,它是一个*timeval。
理解了这个之后,我们来看下面的故事。LuaJIT FFI中,你可以把一个lua函数作为回调函数传回FFI中,例如:
|
1 2 3 4 5 6 7 8 9 |
local ffi = require("ffi") ffi.cdef [[ typedef void (*callback)(int param); int function invoke(callback cb, int a); ]] ffi.C.invoke(function(param) -- do something end, 1) |
当然在C里,你也可以:
|
1 2 3 4 5 6 7 |
typedef void (callback)(int param); int function invoke(callback *cb, int a); void function myCallback(int a) { } invoke(myCallback, 1); |
这样在FFI里可以写成:
|
1 2 3 4 5 6 7 8 9 10 |
local ffi = require("ffi") ffi.cdef [[ typedef void (callback2)(int param); int function invoke(callback2 *cb, int a); ]] local pp = ffi.cast("callback2*", function(param) -- do something end end) ffi.C.invoke(pp, 1) pp:free() |
看起来没问题对吧,但是我们如果我们多次循环ffi.cast:
|
1 2 3 4 5 6 7 8 9 |
while true do local pok, pp = pcall(ffi.cast, "cb1*", function() end) if not pok then print(pp) break end if pp then pp:free() end end |
最终会报错”table overflow”,这个错误来自https://github.com/LuaJIT/LuaJIT/blob/1e66d0f9e6698fdee672c40a9a5b4159c9254091/src/lj_ctype.c#L158,因为某种原因存储ctypes的表被填满了。它的上限是65535。我们来看看它被什么填满了:
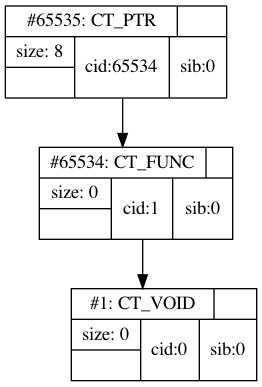
是一个匿名指针,指向一个匿名函数,它的返回值是void。毫无疑问我们的ffi.cast(“callback2*”, …)会在每次调用时创建两个新的ctype。
在LuaJIT的代码里,ffi.cdef,ffi.new,ffi.cast都会经过同一段C parser的代码段lj_cparse的cp_decl_intern函数里,因为除了在cdef中定义类型外,我们也可以在new和cast里定义匿名结构体,所以这些函数都能产生新的ctype。
在这个函数里,当一个符号被认定为function,它就会无条件地新建一个新的ctype。在我们的写法里,typedef void (callback2)(int param);定义了一个名为callback2的“函数类型”,然后在ffi.cast里,cparser解析了callback2,为它创建了一个新的CT_FUNC类型,然后解析了*,新建了一个指针指向新的CT_FUNC。
实际上,LuaJIT确实是可以通过一些额外的标志位来使ffi.cast不会创建新的函数类型的。CType这个类型可以增加一个新的成员,来记录自己的id,通过这种办法,当解析为CT_FUNC时,如果这个id已赋值,则可以直接使用已有的ctype。我尝试了一个简单的patch来验证我的想法,证明了它的可行性;但是没有跑完整的测试集。
我在issues里提问了这个问题,Mike Pall小哥热心地回复了我。当然作者选择目前这种做法确实是更简洁的;而且本身对“函数类型”的typedef,可以有不同角度的理解。所以以后记得写回调函数的时候,定义一个正常的“函数指针”就好了。
